
Humanity's Last Exam (HLE) là benchmark AI gồm 2,500 câu hỏi cấp chuyên gia, được thiết kế để đo khả năng suy luận nhiều bước của các model ngôn ngữ lớn (LLM). Benchmark này ra đời cuối năm 2024, do Dan Hendrycks từ Centre for AI Safety phối hợp với Scale AI phát triển, nhằm thay thế các bài test cũ đã bị model AI vượt qua dễ dàng.
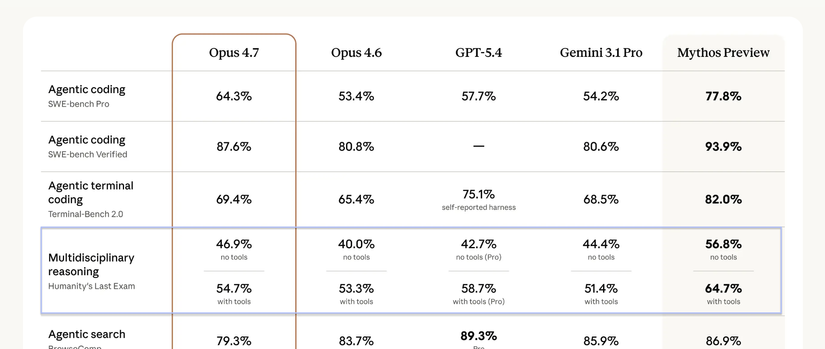 Multidisciplinary response - Humanity's Last Exam với Claude Opus 4.7
Multidisciplinary response - Humanity's Last Exam với Claude Opus 4.7
Tóm tắc các điểm chính##
- HLE gồm 2,500 câu hỏi public và khoảng 500 câu private, crowdsource từ chuyên gia nhiều lĩnh vực học thuật, với giải thưởng lên đến $5,000 cho top contributors
- Benchmark cũ như MMLU đã bão hòa khi model thường xuyên đạt trên 90%, khiến chúng không còn khả năng phân biệt sự khác nhau giữa các model
- Khoảng 76% câu hỏi HLE dạng exact-match (đáp án chính xác), 24% multiple choice, và 14% là multimodal kết hợp cả text lẫn hình ảnh
- Phê phán đáng chú ý: Future House phát hiện khoảng 30% đáp án chemistry/biology trong HLE có thể sai do quy trình review chỉ cho phép 5 phút mỗi câu
- HLE nằm trong hệ sinh thái benchmark rộng hơn gồm MMLU, GPQA, SWE-bench, HELM và các framework đánh giá an toàn AI
Tại sao cần một "bài thi cuối cùng" cho AI?
Benchmark AI hoạt động giống như bài thi chuẩn hóa: chúng cung cấp bộ câu hỏi thống nhất để so sánh hiệu suất giữa các model. Vấn đề là các bài thi cũ đã trở nên quá dễ.
MMLU (Massive Multitask Language Understanding), một trong những benchmark phổ biến nhất, kiểm tra kiến thức trên 57 lĩnh vực khác nhau. Khi MMLU ra đời, nó là thước đo hữu ích để phân biệt model mạnh và yếu. Nhưng đến nay, các model hàng đầu thường xuyên đạt trên 90% trên MMLU. Khi tất cả "thí sinh" đều đạt điểm gần tối đa, bài thi mất đi khả năng đo lường sự khác biệt có ý nghĩa.
Đây chính xác là lý do HLE ra đời. Thay vì kiểm tra kiến thức mà model có thể "nhớ" từ dữ liệu huấn luyện, HLE tập trung vào suy luận nhiều bước. Mỗi câu hỏi yêu cầu model phải kết hợp thông tin, phân tích logic và đưa ra kết luận qua nhiều bước liên tiếp, không thể đoán mò hay tra cứu đơn giản.
HLE được phát triển như thế nào?
Centre for AI Safety, tổ chức phi lợi nhuận chuyên về an toàn AI, đã hợp tác với Scale AI để xây dựng HLE vào cuối năm 2024. Dan Hendrycks dẫn dắt dự án này.
Đội ngũ phát triển sử dụng phương pháp crowdsource: họ kêu gọi chuyên gia từ nhiều lĩnh vực học thuật đóng góp câu hỏi cấp graduate-level. Để khuyến khích chất lượng cao, chương trình trao giải thưởng đáng kể. Top 50 người đóng góp tốt nhất nhận $5,000 mỗi người, và 500 người tiếp theo nhận $500.
Kết quả là một kho câu hỏi chuyên gia trải rộng trên nhiều môn: toán học, khoa học máy tính, văn học, phân tích âm nhạc và lịch sử.
Quy trình sàng lọc câu hỏi HLE diễn ra thế nào?
HLE có quy trình vetting khá nghiêm ngặt, diễn ra qua bốn giai đoạn lọc dần từ hàng chục nghìn câu xuống còn 3,000.
Giai đoạn đầu tiên yêu cầu mỗi câu hỏi phải "đánh bại" được một model AI hàng đầu. Khoảng 70,000 câu hỏi đáp ứng tiêu chí này. Giai đoạn thứ hai đưa các câu hỏi qua expert peer review, nơi các chuyên gia cùng lĩnh vực đánh giá và lọc xuống còn 13,000 câu. Giai đoạn thứ ba do ban tổ chức và expert reviewers duyệt thủ công, chọn ra 6,000 câu hỏi đạt chuẩn. Cuối cùng, đội ngũ nghiên cứu chia pool này thành 2,500 câu hỏi public và khoảng 500 câu holdout dùng cho đánh giá riêng.
Mỗi câu hỏi trong HLE phải đáp ứng ba tiêu chí bắt buộc: phải là câu hỏi gốc (original), chỉ có duy nhất một đáp án đúng, và không thể trả lời bằng cách tìm kiếm web đơn giản.
HLE gồm những gì?
HLE tự mô tả là "bài thi closed-ended cuối cùng cho kỹ năng học thuật tổng quát." Cấu trúc benchmark gồm hai phần chính:
Bộ câu hỏi public gồm 2,500 câu được công khai cho cộng đồng nghiên cứu. Bộ holdout gồm khoảng 500 câu được giữ riêng để tránh tình trạng model bị "train" trực tiếp trên đề thi.
Về định dạng, khoảng 76% câu hỏi sử dụng format exact-match, nghĩa là model phải đưa ra đáp án chính xác, không có lựa chọn gợi ý. 24% còn lại là multiple choice. Đặc biệt, khoảng 14% câu hỏi là multimodal, kết hợp cả text và hình ảnh, đòi hỏi model phải xử lý thông tin từ nhiều dạng dữ liệu.
Những phê phán đáng chú ý về HLE
HLE không phải không có vấn đề. Kết quả ban đầu cho thấy một hiện tượng đáng lo ngại: các model hàng đầu đạt điểm rất thấp trên HLE nhưng lại thể hiện độ tự tin rất cao trong câu trả lời. Khoảng cách giữa "tự tin" và "chính xác" này chính là dấu hiệu điển hình của hallucination.
Future House, phòng nghiên cứu phi lợi nhuận, đã công bố phân tích gây chấn động: khoảng 30% đáp án chemistry/biology trong HLE có thể sai. Nguyên nhân nằm ở quy trình review. Người viết câu hỏi tự khai báo đáp án đúng, nhưng reviewer chỉ được phân bổ khoảng 5 phút để kiểm tra tính chính xác của mỗi đáp án. Future House cho rằng quy trình này để lọt các đáp án quá phức tạp, gượng ép hoặc mơ hồ, thậm chí mâu thuẫn với tài liệu khoa học đã được công bố.
Đội ngũ HLE đã phản hồi bằng cách ủy quyền cho ba chuyên gia review lại subset bị tranh cãi. Tính đến tháng 9/2025, họ dự kiến triển khai quy trình rolling review liên tục cho HLE.
Bức tranh toàn cảnh benchmark AI hiện nay như thế nào?
HLE không tồn tại độc lập mà nằm trong một hệ sinh thái benchmark rộng lớn, mỗi loại đo lường một khía cạnh khác nhau của khả năng AI.
Benchmark đo kiến thức và suy luận
| Benchmark | Mô tả | Đặc điểm |
|---|---|---|
| MMLU | Kiểm tra zero-shot trên 57 lĩnh vực | Đã bão hòa, model đạt 90%+ |
| MMLU-Pro/Pro+ | Nâng cấp MMLU với câu hỏi phức tạp hơn | Tập trung higher-order reasoning |
| GPQA (Google Proof Q&A) | 448 câu hỏi STEM cấp graduate | Thiết kế để "Google-proof" |
| HLE | 2,500 câu hỏi từ chuyên gia nhiều lĩnh vực | Nhấn mạnh suy luận, không phải nhớ |
Benchmark đo hiểu đa phương thức (multimodal)
MMMU (Massive Multi-discipline Multimodal Understanding) gồm khoảng 1,500 câu hỏi kết hợp text và hình ảnh, lấy từ đề thi, quiz và giáo trình. Phiên bản nâng cấp MMMU-Pro loại bỏ những câu có thể giải chỉ bằng text, thêm nhiều lựa chọn đáp án hơn, và giới thiệu chế độ vision-only khi toàn bộ prompt được nhúng trong hình ảnh.
Benchmark đo kỹ năng lập trình
SWE-bench là benchmark xây dựng từ các GitHub issues thực tế trên 12 repository Python. Model phải đọc codebase, hiểu mô tả lỗi và đề xuất bản vá. Các phiên bản nâng cấp bao gồm SWE-bench Verified (sửa lỗi test quá cụ thể, làm rõ mô tả mơ hồ) và SWE-bench-Live (cập nhật liên tục với 1,319 tasks trên 93 repos).
Framework đánh giá toàn diện
HELM (Holistic Evaluation of Language Models) do Stanford CRFM phát triển, đánh giá model trên nhiều kịch bản chuẩn hóa: trả lời câu hỏi, tóm tắt, safety và nội dung đạo đức. HELM chấm điểm trên nhiều chiều, không chỉ độ chính xác mà còn calibration, robustness và toxicity. HELM đã phát triển thành nhiều phiên bản chuyên biệt: HELM Lite (đánh giá nhanh), HELM Finance (tài chính) và MedHELM (y tế).
Framework đánh giá an toàn AI
METR (Model Evaluation & Threat Research) là tổ chức phi lợi nhuận đánh giá các khả năng nguy hiểm tiềm tàng: tấn công mạng, cố gắng tránh bị tắt, hoặc khả năng tự động hóa nghiên cứu AI. Mục tiêu của METR là phát hiện sớm rủi ro thảm họa. Song song đó, Google DeepMind xây dựng Frontier Safety Framework định nghĩa các ngưỡng năng lực quan trọng (Critical Capability Levels), theo dõi khi model tiếp cận các ngưỡng này và triển khai kế hoạch giảm thiểu rủi ro.
HLE được sử dụng trong thực tế như thế nào?
HLE phục vụ hai nhóm đối tượng chính với mục đích khác nhau.
Đối với đội ngũ nghiên cứu
HLE cung cấp phương pháp đánh giá chuẩn hóa trên nhiều lĩnh vực. Benchmark này giúp làm rõ điểm mạnh và điểm yếu của từng model, đồng thời cho thấy khoảng cách giữa AI và hiệu suất chuyên gia con người. Các đội ngũ có thể sử dụng những pattern này để định hướng phát triển model và tập trung post-training vào đúng điểm yếu.
Đối với nhà hoạch định chính sách
HLE tạo ra một thước đo công khai, toàn cầu về tiến bộ suy luận AI. Benchmark này tạo điểm tham chiếu chung giữa các quốc gia và cơ quan quản lý, giúp neo các cuộc thảo luận về ngưỡng an toàn, giám sát và quản trị vào dữ liệu thực tế thay vì chỉ dựa trên hype.
Kết luận
Benchmark AI định hình cách chúng ta đo lường tiến bộ trí tuệ nhân tạo. Khi các benchmark cũ như MMLU đã bão hòa, nhu cầu về một bài test mới tập trung vào suy luận thay vì nhớ hay pattern matching trở nên rõ ràng.
HLE cố gắng lấp khoảng trống đó bằng cách crowdsource câu hỏi cấp graduate từ chuyên gia trên toàn cầu để phơi bày giới hạn thực sự của LLM. Dù vẫn còn vấn đề cần cải thiện như quy trình review đáp án, HLE vẫn là một công cụ hữu ích để làm rõ AI đang đứng ở đâu so với khả năng suy luận chuyên gia con người.
Câu hỏi thường gặp
Humanity's Last Exam (HLE) là gì?
HLE là benchmark gồm 2,500 câu hỏi học thuật cấp chuyên gia, thiết kế để kiểm tra khả năng suy luận nhiều bước của LLM trên nhiều lĩnh vực. Benchmark này do Centre for AI Safety và Scale AI phát triển vào cuối năm 2024.
Tại sao không dùng các benchmark cũ như MMLU?
MMLU và nhiều benchmark truyền thống đã bão hòa khi các model hàng đầu thường xuyên đạt trên 90%. Ở mức điểm này, benchmark không còn phân biệt được sự khác nhau giữa các model, nên cần một bài test khó hơn tập trung vào suy luận.
HLE có nhược điểm gì không?
Có. Future House phát hiện khoảng 30% đáp án chemistry/biology trong HLE có thể sai, do quy trình review chỉ cho phép reviewer 5 phút mỗi câu. Đội ngũ HLE đã phản hồi và dự kiến triển khai rolling review liên tục.
HLE khác gì so với các benchmark khác?
HLE tập trung vào câu hỏi expert-level yêu cầu suy luận nhiều bước, trong khi MMLU kiểm tra kiến thức tổng quát, SWE-bench đo kỹ năng lập trình, và HELM đánh giá toàn diện trên nhiều chiều (accuracy, robustness, toxicity). Mỗi benchmark đo một khía cạnh khác nhau và bổ sung cho nhau.

![[Open Source] #235 - LinkStack: Nền tảng Link-in-bio tự vận hành với kiến trúc Laravel 9, Livewire và hệ thống "Blocks" linh hoạt](https://images.viblo.asia/3815aed7-b285-4471-90c1-8a3a002107fc.png)