
Hôm nay mình muốn chia sẻ một chút về AWS — một nền tảng cloud mà mình dùng khá nhiều trong công việc cũng như học tập. Không chỉ giúp mình triển khai hệ thống, AWS còn ảnh hưởng khá nhiều đến cách mình tư duy về thiết kế kiến trúc và các giải pháp kỹ thuật trong thực tế.
Nếu thấy hay, kết nối với mình tại LinkedIn
Trước đây mình từng viết một bài về cách tối ưu chi phí hạ tầng AWS trong doanh nghiệp, với một số tư duy giúp giảm hóa đơn cloud xuống khoảng 40% mà hệ thống vẫn hoạt động ổn định. Trong bài này, mình sẽ nói về một “bộ đôi” mà mình dùng rất thường xuyên cho automation: EventBridge và Lambda. Hai service này kết hợp với nhau khá gọn nhẹ nhưng lại giải quyết được rất nhiều bài toán thực tế.

0. Tìm hiểu qua bộ đôi này là gì đã nhé
Lambda là gì?
Hiểu đơn giản, AWS Lambda là một dịch vụ cho phép bạn chạy code mà không cần quản lý server. Bạn chỉ cần viết code để xử lý logic business, AWS sẽ lo phần còn lại như provisioning, scaling hay vận hành hạ tầng.
Tuy nhiên, “không cần quản lý server” không có nghĩa là bạn không cần quan tâm gì. Trong thực tế, bạn vẫn cần cấu hình một số thứ như memory, timeout, IAM permissions hoặc tối ưu để giảm cold start.
Thông thường, bạn sẽ viết code dưới dạng một function (entry point gọi là handler), Lambda sẽ thực thi function này khi có event trigger. Lambda hỗ trợ nhiều runtime như Node.js, Python, Java…, và với mình thì Node.js là lựa chọn ưu tiên vì quen tay và có cold start khá nhanh trong nhiều trường hợp.
Ứng dụng của Lambda thì rất nhiều, nhưng trong phạm vi bài này mình chỉ tập trung vào automation kết hợp với EventBridge thôi nhé ;).
EventBridge là gì?
EventBridge là một dịch vụ xử lý event trong AWS. Nó cho phép bạn nhận các sự kiện từ nhiều nguồn khác nhau như AWS services, CloudTrail, hoặc custom events do chính bạn gửi vào.
Một điểm quan trọng là EventBridge không “can thiệp” trực tiếp vào hệ thống. Thay vào đó, nó hoạt động như một event router: khi một sự kiện xảy ra, bạn định nghĩa rule để bắt sự kiện đó và trigger các target tương ứng (ví dụ như Lambda, SQS, Step Functions…).
Trong bài này, mình sẽ chỉ tập trung vào tính năng Schedule của EventBridge — tức là chạy job theo thời gian (cron hoặc rate). Đây là một cách rất tiện để xây dựng các tác vụ tự động định kỳ mà không cần setup server riêng.
Vì sao mình hay dùng bộ đôi này?
Với mình, EventBridge + Lambda là một combo rất “gọn nhẹ” để làm automation:
- Không cần dựng server cron riêng
- Dễ scale
- Chi phí thấp nếu workload không lớn
- Tích hợp sẵn trong hệ sinh thái AWS
Trong nhiều case thực tế, chỉ cần một rule schedule + một Lambda function là có thể giải quyết được cả một bài toán vận hành.
1. Quản lý và tối ưu chi phí hạ tầng
Đây là nhóm use-case gần như phổ biến nhất khi làm Cloud, đặc biệt nếu anh em đang vận hành nhiều môi trường (dev, staging, sandbox…). Làm tốt phần này thì không chỉ tiết kiệm được kha khá chi phí mà còn giúp team vận hành đỡ phải “canh budget” mỗi cuối tháng.
Một trong những cách mình dùng nhiều nhất là tự động tắt/mở tài nguyên theo khung giờ. Cụ thể, mình sẽ dùng EventBridge Scheduler để trigger Lambda theo lịch (cron), ví dụ lúc 18h, anh em xong việc thì tắt toàn bộ tài nguyên không cần thiết, sau đó bật lại vào 8h sáng hôm sau.
Áp dụng chủ yếu cho các môi trường Development hoặc Staging. Các resource phù hợp với cách này:
- EC2 → dễ nhất, stop/start trực tiếp
- RDS → có thể stop/start, nhưng cần lưu ý AWS chỉ cho stop tối đa 7 ngày, sau đó sẽ tự bật lại
- ASG → không có khái niệm “tắt”, mà sẽ set desired capacity về 0 (hoặc scale down theo lịch)
- ECS → thường mình sẽ:
- set desired count của service về 0 để “tắt”
- khi bật lại thì scale lên như cũ
- nếu dùng Fargate thì cách này rất hiệu quả vì scale = 0 là gần như không tốn compute
- EKS → chờ anh em bổ sung, hiện tại mình đang làm với ECS thôi
Ngoài việc bật/tắt theo lịch, một bài toán rất hay bị bỏ quên là dọn dẹp tài nguyên “rác”. Mình thường setup một job chạy định kỳ (ví dụ mỗi ngày hoặc mỗi tuần) để:
- Quét các EBS Volume không còn attach vào EC2
- Xóa các snapshot quá cũ (ví dụ > 30 ngày)
- Dọn các Elastic IP không còn gắn với resource nào
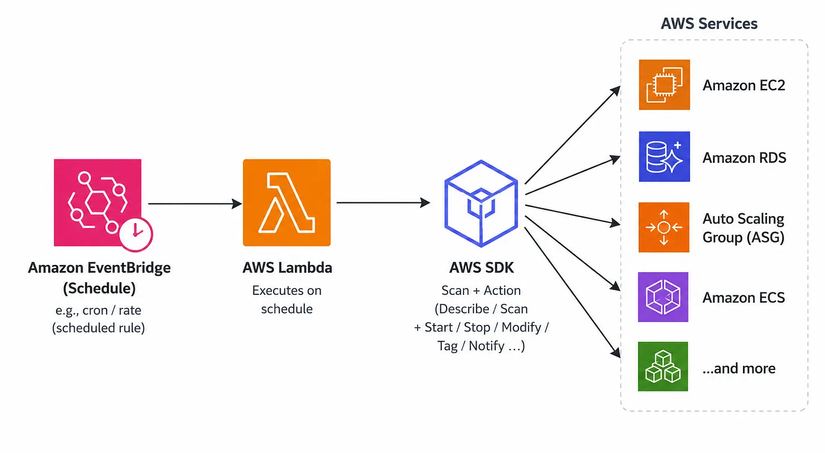
Nghe thì đơn giản, nhưng phần này nếu làm linh tinh không cẩn thận là rất dễ toang 😅. Kinh nghiệm của mình là luôn filter theo tag (vd: env=dev, auto-clean=true), hoặc theo rule rõ ràng (age, owner, project), tránh xóa các tài nguyên này mà chỉ dựa vào trạng thái. Vì thực tế có nhiều resource nhìn thì “không dùng” nhưng:
- đang chờ attach
- là backup để phục vụ rollback
- hoặc thuộc quy trình compliance
Toàn bộ flow này thường mình sẽ để:
EventBridge (schedule) → Lambda → AWS SDK (scan + action)
Setup xong gần như chạy tự động hoàn toàn, vừa tiết kiệm chi phí, vừa giảm kha khá manual work cho team vận hành.
2. Xử lý dữ liệu và tập tin
Trong thực tế, mình khá hay gặp bài toán xử lý dữ liệu từ bên thứ 3. Thường thì họ sẽ cung cấp một file dữ liệu khá lớn (CSV, JSON dump…), nhưng phía mình chỉ cần một phần nhỏ dữ liệu bên trong để phục vụ business.
Nếu cứ load toàn bộ file về rồi xử lý trực tiếp trên server thì vừa tốn tài nguyên, vừa không tối ưu — đặc biệt khi dữ liệu này lại được cập nhật hàng ngày. Lúc đó mình phải đảm bảo 2 thứ: xử lý đủ nhanh và dữ liệu luôn là bản mới nhất.
Cách mình thường làm là setup một flow ETL đơn giản bằng EventBridge và Lambda. Cụ thể là sẽ dùng EventBridge Scheduler chạy theo lịch (ví dụ mỗi ngày 1 lần). Sau đó là trigger Lambda để thực hiện ETL (Extract – Transform – Load).
Trong Lambda, mình sẽ:
- Extract: lấy dữ liệu từ source (API hoặc file)
- Nếu là file lớn, mình ưu tiên xử lý theo kiểu streaming hoặc chia nhỏ thay vì load toàn bộ vào memory
- Transform: lọc ra đúng phần dữ liệu cần dùng, normalize lại format nếu cần
- Load: ghi dữ liệu đã xử lý vào S3 (làm data lake) hoặc database như RDS / DynamoDB để phục vụ các service khác
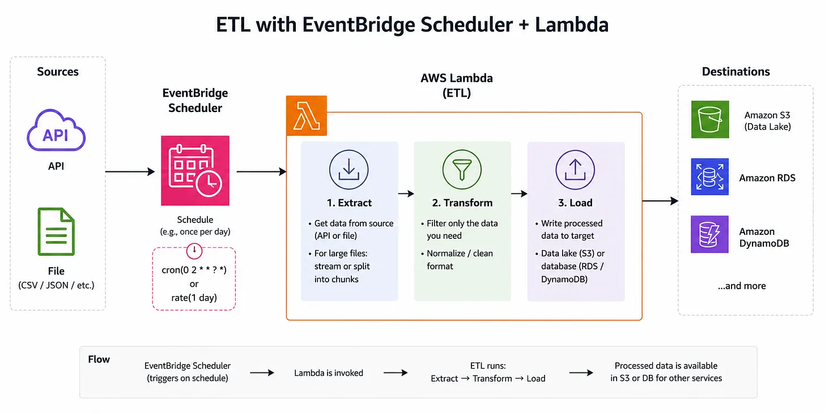
Cách này giúp giảm tải cho các service chính (không phải xử lý data nặng lúc runtime). Dữ liệu luôn được chuẩn bị sẵn sàng, chỉ việc query là dùng được ngon luôn và dễ scale và gần như không cần maintain server.
Tuy nhiên, Lambda không phải lúc nào cũng là lựa chọn đúng. Với các job ETL nhỏ hoặc trung bình (data không quá lớn, xử lý trong vài phút) thì Lambda chạy rất ổn. Nhưng nếu file quá lớn (vài GB trở lên) hoặc logic transform phức tạp thì nên cân nhắc chuyển sang AWS Glue (ETL chuyên dụng) hoặc ECS/Fargate job để xử lý batch.
Một điểm mình thấy khá quan trọng nhưng dễ bị bỏ qua là tính “an toàn” của pipeline:
- Nên có retry hoặc DLQ nếu job fail
- Tránh ghi đè dữ liệu một cách mù quáng (có thể partition theo ngày hoặc version)
- Đảm bảo job chạy lại không bị duplicate data (idempotency)
Tổng thể, với những bài toán ETL đơn giản đến trung bình, combo EventBridge + Lambda + S3/DB là một giải pháp rất gọn, dễ triển khai và chi phí cũng khá dễ chịu.
3. Cron Job
Cron job là một trong những thứ gần như doanh nghiệp nào cũng cần dùng, đặc biệt với các tác vụ chạy theo lịch như xử lý batch dữ liệu, đồng bộ dữ liệu, gửi báo cáo định kỳ, hay thực hiện các bước billing theo chu kỳ cho khách hàng.
Trước đây mình cũng từng dùng scheduling ngay trong ứng dụng Spring Boot bằng @Scheduled. Cách này dùng thì được, nhưng khi chạy trong môi trường có nhiều instance, pod hoặc container thì bắt đầu phát sinh vấn đề. Nếu không có cơ chế chống chạy trùng, cùng một job rất dễ bị trigger nhiều lần từ nhiều instance khác nhau.
Ngoài ra, việc debug và vận hành cũng khá bất tiện. Job chạy bên trong app thì log, retry, timeout hay failure đều gắn chặt với runtime của ứng dụng, nên khi cần scale hoặc tách biệt trách nhiệm thì không còn quá ngon lành nữa.
Vì vậy, với những job chạy theo lịch, mình thường tách phần scheduling ra khỏi ứng dụng chính. Cụ thể, mình để EventBridge lo phần schedule, rồi Lambda sẽ là nơi thực thi job.
Flow này khá gọn:
- EventBridge chạy theo lịch đã cấu hình.
- Lambda được invoke để thực hiện một tác vụ cụ thể.
- Lambda có thể gọi API của ứng dụng phía sau ALB, hoặc xử lý trực tiếp logic cần thiết.
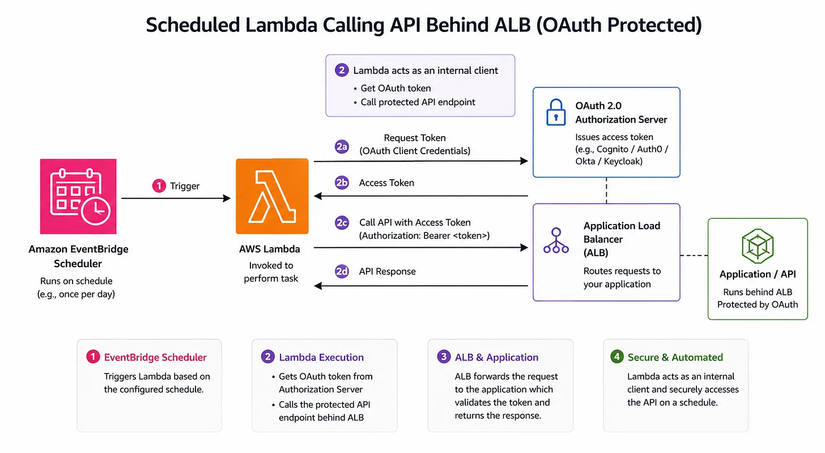
Nếu API được bảo vệ bằng OAuth thì càng ổn, vì Lambda có thể đóng vai trò như một client nội bộ, lấy token rồi gọi vào endpoint một cách an toàn. Cách này có vài điểm mình thấy rất đáng giá:
- Không phải nhúng cron logic vào ứng dụng chính.
- Dễ scale hơn vì schedule nằm tách biệt với runtime của app.
- Giảm rủi ro job bị chạy trùng khi hệ thống có nhiều instance.
- Vận hành và theo dõi cũng rõ ràng hơn.
Nói ngắn gọn, với những job định kỳ cần độ ổn định cao, mình thấy để EventBridge lo schedule và Lambda lo execution là một hướng khá sạch, gọn và dễ maintain.
4. Đồng bộ database staging từ production
Gần đây mình có gặp một task khá thực tế: làm sao để mỗi ngày database ở staging luôn được refresh từ production, để team có thể debug, test và xử lý sự cố trên một bộ dữ liệu gần giống thực tế nhất.
Bài toán này nghe thì đơn giản, nhưng thực ra có vài yêu cầu khá “khó nhằn”:
- Dữ liệu staging phải được cập nhật hàng ngày.
- Endpoint của database staging phải giữ cố định.
- User và password của staging phải giữ nguyên để team dev không phải đổi kết nối liên tục.
- Việc refresh phải tự động, an toàn và ít thao tác tay nhất có thể.
Với bài toán này, mình chọn cách làm bằng EventBridge + Lambda.
Điểm đầu tiên mình cần giải quyết là endpoint cố định. Vì mỗi lần restore từ snapshot, AWS sẽ tạo ra một RDS instance mới với endpoint mới, nên mình không để app connect trực tiếp vào endpoint thật của RDS. Thay vào đó, mình tạo một record CNAME trong Route53 để làm endpoint cố định cho staging. App chỉ cần trỏ vào hostname này, còn phía sau nó sẽ redirect đến instance staging mới nhất.
Flow mình chia làm 2 bước.
Flow 1: Restore staging mới
Vào mỗi ngày N, Lambda sẽ restore một snapshot mới nhất từ production để tạo ra một RDS instance staging mới. Instance này sẽ là bản staging của ngày hôm đó, với dữ liệu được cập nhật theo production gần nhất.
Flow 2: Chuẩn hóa và chuyển hướng
Sau khoảng 30 phút, khi instance mới đã restore xong và chuyển sang trạng thái available, Lambda sẽ tiếp tục được kích hoạt và làm 3 việc:
- Reset password của database staging về giá trị đã được định nghĩa sẵn.
- Cập nhật CNAME trong Route 53 để trỏ sang endpoint mới của instance vừa restore.
- Xóa database staging của ngày
N-1để tránh tốn chi phí.
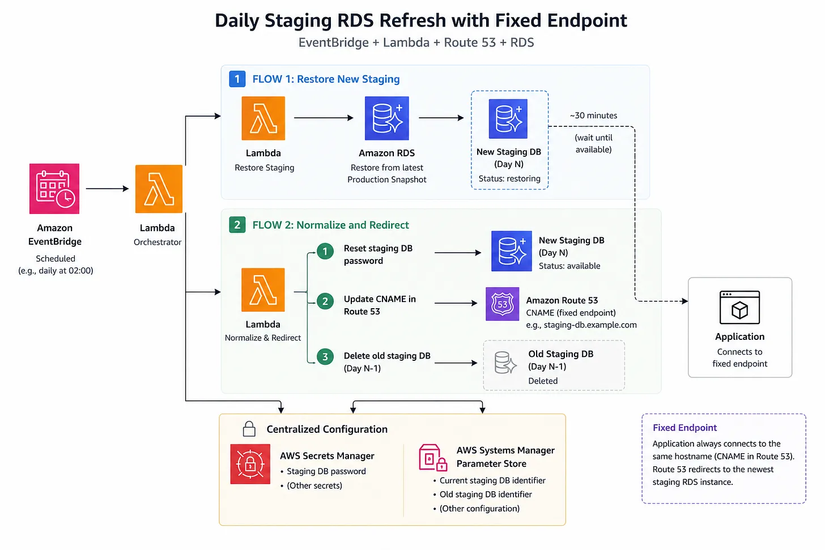
Toàn bộ thông tin cần thiết như password, database identifier của staging hiện tại và staging cũ đều được quản lý tập trung trong Secrets Manager và Parameter Store. Cách này giúp việc vận hành an toàn hơn và cũng dễ kiểm soát hơn khi cần trace lại trạng thái của hệ thống.
Cuối cùng, toàn bộ workflow này đều được EventBridge schedule theo giờ mình lựa chọn, nên gần như không cần can thiệp thủ công mỗi ngày.
5. Bảo mật và tuân thủ
Một trong những giá trị lớn của automation trên AWS là giúp doanh nghiệp phản ứng nhanh hơn với các rủi ro bảo mật, thay vì phải chờ người vận hành phát hiện và xử lý thủ công. Một số tình huống mình thường nghĩ tới là:
- Có IAM user mới được tạo ra nhưng không đúng quy trình.
- Một IAM role được gán quyền quá rộng, ví dụ
AdministratorAccess. - Một S3 bucket bị chuyển sang chế độ
publicngoài ý muốn.
Với các case như vậy, mình có thể dùng EventBridge để nhận các sự kiện bảo mật được ghi nhận qua CloudTrail, sau đó trigger Lambda để xử lý tự động theo rule đã định nghĩa trước. Flow thường sẽ là:
- CloudTrail ghi nhận sự kiện thay đổi.
- EventBridge bắt event đó và kích hoạt Lambda.
- Lambda thực hiện remediation, ví dụ thu hồi quyền, đưa cấu hình về trạng thái an toàn, hoặc gửi cảnh báo cho team vận hành.
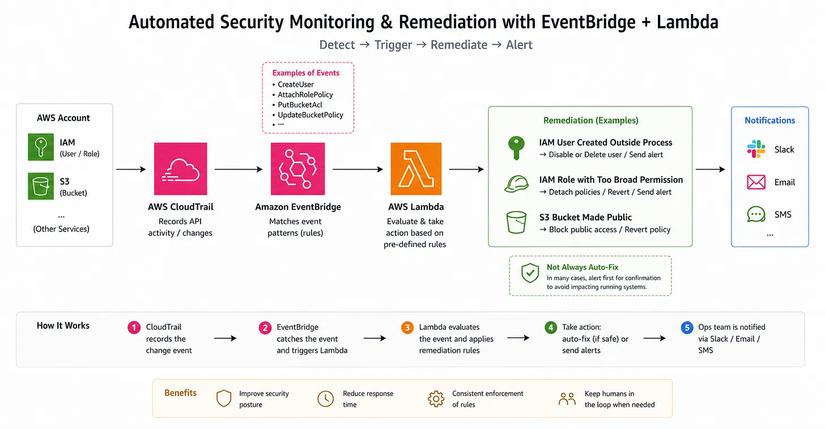
Trong nhiều trường hợp, mình không nhất thiết auto-fix mọi thứ ngay lập tức. Có những tình huống chỉ nên cảnh báo qua Slack, email hoặc SMS trước để team xác nhận, nhất là khi hành động sửa tự động có thể ảnh hưởng tới hệ thống đang chạy.
Cách làm này giúp team bảo mật và CloudOps phản ứng nhanh hơn, giảm thời gian phơi nhiễm rủi ro và giữ cho hệ thống bám sát chính sách an toàn hơn.
6. Extra use cases
Ngoài những case mình đã nói ở trên, EventBridge + Lambda còn có khá nhiều ứng dụng nhỏ nhưng rất thực tế trong vận hành hệ thống. Đây là kiểu automation không quá “hoành tráng”, nhưng lại giúp giảm rất nhiều manual work cho team.
Một số case mình thấy khá hữu ích: Tự động gửi báo cáo định kỳ Ví dụ mỗi sáng Lambda chạy để tổng hợp số liệu từ database, S3 hoặc API nội bộ, rồi gửi report qua email hoặc Slack cho team.
Health check theo lịch EventBridge trigger Lambda để gọi vào API / endpoint quan trọng. Nếu endpoint có vấn đề thì gửi cảnh báo ngay cho team vận hành.
Xử lý các job nhẹ Ví dụ đồng bộ trạng thái giữa các hệ thống, kiểm tra dữ liệu lệch, hoặc cập nhật lại record chưa đúng trạng thái.
Tự động kiểm tra và nhắc xoay vòng secret Nếu secret hoặc API key sắp hết hạn, Lambda có thể gửi cảnh báo để team xử lý trước khi ảnh hưởng tới production.
Điều phối các tác vụ nhỏ theo lịch Với những workflow đơn giản, mình có thể để EventBridge trigger Lambda theo từng bước thay vì phải dựng hẳn một workflow engine nặng hơn.
Điểm mình thích ở combo này là nó rất gọn. Không cần dựng thêm server, không phải maintain cron trên máy riêng, mà vẫn giải quyết được khá nhiều bài toán vận hành thực tế.
Nếu một use case đã bắt đầu phức tạp hơn, nhiều nhánh hơn, hoặc cần orchestration rõ ràng hơn, thì lúc đó mình mới cân nhắc chuyển sang Step Functions hoặc một giải pháp workflow khác.
Kết
Tổng lại, mình thấy EventBridge + Lambda là một bộ đôi rất đáng dùng nếu bạn muốn tự động hóa các tác vụ vận hành, xử lý dữ liệu, cron job hay cả một số luồng bảo mật đơn giản trong AWS. Điểm mạnh của nó là gọn, ít phải quản lý hạ tầng, dễ mở rộng và phù hợp với rất nhiều bài toán thực tế.
Tất nhiên, không phải case nào cũng nên dùng Lambda. Nếu job quá nặng, chạy quá lâu, hoặc workflow quá phức tạp thì mình sẽ cân nhắc sang Glue, ECS, Step Functions hoặc một giải pháp phù hợp hơn. Nhưng với những bài toán vừa và nhỏ, nhất là các tác vụ theo lịch hoặc trigger theo sự kiện, thì combo này thực sự rất “đáng đồng tiền bát gạo”.
Mình viết bài này không phải để nói rằng đây là cách duy nhất đúng, mà là một cách mình đã dùng khá nhiều trong thực tế và thấy nó hiệu quả. Nếu anh em có cách làm nào hay hơn, tối ưu hơn, hoặc có kinh nghiệm thực chiến khác với EventBridge và Lambda thì rất muốn được học thêm.
Bài viết này cũng được mình dịch sang tiếng Anh trên blog substack của mình.
Mình viết lại những điều này như một cách để ghi nhớ hành trình làm nghề của mình. Nếu bạn cũng đang làm backend, devops hoặc cloud, hy vọng những chia sẻ này có thể giúp bạn một chút gì đó. Còn nếu có chỗ nào mình hiểu chưa đúng, mình vẫn luôn sẵn sàng học thêm.


